




Note that we are defining portability in terms of a set of target
machines and not as some universal property. The act of modifying
an existing program to make it portable to a new target machine is
called porting. Clearly in the examples above, porting the first program
would be a highly complex task involving almost an entire rewrite,
whereas in the second case it should be trivial.
The second point is that the second example program is not in itself
complete. The objects
A version of this file is to be found on each target machine. On a
particular machine it might contain something like:
These details are fed into the program by the pre-processing phase
of the compiler. (The various compilation phases are discussed in
more detail later - see Fig. 1.) This is a simple, preliminary textual
substitution. It provides the definitions of the type
Note that, even after the pre-processing phase, our portable program
has been transformed into a target dependent form, because of the
substitution of the target dependent values from
To conclude, we have, by including
The interface for the "Hello world" program above might
be described as follows : defined in the header
The benefit of describing the API at this fairly high level is that
it leaves scope for a range of implementation (and thus more machines
which implement it) while still encapsulating the main program's requirements.
In the example implementation of
Another way of defining an API for this program would be to note that
the given API is a subset of the ANSI C standard. Thus we could take
ANSI C as an "off the shelf" API. It is then clear that
our program should be portable to any ANSI-compliant machine.
It is worth emphasising that all programs have an API, even if it
is implicit rather than explicit. However it is probably fair to say
that programs without an explicit API are only portable by accident.
We shall have more to say on this subject later.
FIGURE 1. Traditional Compilation Phases
The compilation is divided into three main phases. Firstly the system
headers are inserted into the program by the pre-processor. This produces,
in effect, a target dependent version of the original program. This
is then compiled into a binary object file. During the compilation
process the compiler inserts all the information it has about the
machine - including the Application Binary Interface (ABI) - the sizes
of the basic C types, how they are combined into compound types, the
system procedure calling conventions and so on. This ensures that
in the final linking phase the binary object file and the system libraries
are obeying the same ABI, thereby producing a valid executable. (On
a dynamically linked system this final linking phase takes place partially
at run time rather than at compile time, but this does not really
affect the general scheme.)
The compilation scheme just described consists of a series of phases
of two types ; code combination (the pre-processing and system linking
phases) and code transformation (the actual compilation phases). The
existence of the combination phases allows for the effective separation
of the target independent code (in this case, the whole program) from
the target dependent code (in this case, the API implementation),
thereby aiding the construction of portable programs. These ideas
on the separation, combination and transformation of code underlie
the TDF approach to portability.
Many of these built-in assumptions may arise because of the conventional
porting process. A program is written on one machine, modified slightly
to make it work on a second machine, and so on. This means that the
program is "biased" towards the existing set of target machines,
and most particularly to the original machine it was written on. This
applies not only to assumptions about endianness, say, but also to
the questions of API conformance which we will be discussing below.
Most compilers will pick up some of the grosser programming errors,
particularly by type checking (including procedure arguments if prototypes
are used). Some of the subtler errors can be detected using the -Wall
option to the Free Software Foundation's GNU C Compiler (
Note that in Fig. 1 all the actual compilation takes place on the
target machine. So, to port the program to n machines, we need
to deal with the bugs and limitations of n, potentially different,
compilers. For example, if you have written your program using prototypes,
it is going to be a large and rather tedious job porting it to a compiler
which does not have prototypes (this particular example can be automated;
not all such jobs can). Other compiler limitations can be surprising
- not understanding the
The differing compiler interpretations may be more subtle. For example,
there are differences between ANSI and "traditional" C which
may trap the unwary. Examples are the promotion of integral types
and the resolution of the linkage of static objects.
Many of these problems may be reduced by using the "same"
compiler on all the target machines. For example,
The first code combination phase is the pre-processor pulling in the
system headers. These can contain some nasty surprises. For example,
consider a simple ANSI compliant program which contains a linked list
of strings arranged in alphabetical order. This might also contain
a routine:
In reality the system headers on any given machine are a hodge podge
of implementations of different APIs, and it is often virtually impossible
to separate them (feature test macros such as
A second example demonstrates a slightly different point. The POSIX
standard states that
The problem here is not with the program or the implementation, but
in the way they were combined. C does not allow individual field selectors
to be defined. Instead the indiscriminate sledgehammer of macro substitution
was used, leading to the problem described.
Problems can also occur in the other combination phase of the traditional
compilation scheme, the system linking. Consider the ANSI compliant
routine:
The reason for this lies in the system linking. On those machines
which failed the library routine
So code combination problems are primarily namespace problems. The
task of combining the program with the API implementation on a given
platform is complicated by the fact that, because the system headers
and system libraries contain things other than the API implementation,
or even because of the particular implementation chosen, the various
namespaces in which the program is expected to operate become "polluted".
Recall from above that the system headers on a given machine are an
amalgam of all the APIs it implements. This can cause programs which
should compile not to, because of namespace clashes; but it may also
cause programs to compile which should not, because they have used
objects which are not in their API, but which are in the system headers.
For example, the supposedly ANSI compliant program:
The previous examples have been concerned with simply telling whether
or not a particular object is in an API. A more difficult, and in
a way more important, problem is that of assuming too much about the
objects which are in the API. For example, in the program:
A common example (one which I have to include a workaround for in
virtually every program I write) is that
As an example of things being defined in the wrong place, ANSI specifies
that
A final syntactic problem, which perhaps should belong with the system
header problems above, concerns dependencies between the headers themselves.
For example, the POSIX header
There can also be semantic errors in the system headers : namely wrongly
defined values. The following two examples are taken from real operating
systems. Firstly the definition:
Of course this all depends on the behaviour of
Once the problem has been identified as being with
The only alternative to this trial and error approach to finding API
implementation problems is the application of personal experience,
either of the particular target machine or of things that are implemented
wrongly by many machines and as such should be avoided. This sort
of detailed knowledge is not easily acquired. Nor can it ever be complete:
new operating system releases are becoming increasingly regular and
are on occasions quite as likely to introduce new implementation errors
as to solve existing ones. It is in short a "black art".
So the API in this case has two components : a system-defined part
which is implemented in the system headers and system libraries, and
a user-defined part which ultimately relies on the person performing
the compilation to provide an implementation. The main point to be
made in this section is that introducing target dependent code is
equivalent to introducing a user-defined component to the API. The
actual compilation process in the case of programs containing target
dependent code is basically the same as that shown in Fig. 1. But
whereas previously the vertical division of the diagram also reflects
a division of responsibility - the left hand side is the responsibility
of the programmer (the person writing the program), and the right
hand side of the API specifier (for example, a standards defining
body) and the API implementor (the system vendor) - now the right
hand side is partially the responsibility of the programmer and the
person performing the compilation. The programmer specifies the user-defined
component of the API, and the person compiling the program either
implements this API (as in the mips example above) or chooses between
a number of alternative implementations provided by the programmer
(as in the example below).
Let us consider a more complex example. Consider the following program
which assumes, for simplicity, that an
The person compiling the program has to choose between the three possible
implementations of
There are two possible ways of looking at what the user-defined API
of this program is. Possibly it is most natural to say that it is
Another advantage of specifying the requirements of a program is that
it may increase their chances of being implemented. We have spoken
as if porting is a one-way process; program writers porting their
programs to new machines. But there is also traffic the other way.
Machine vendors may wish certain programs to be ported to their machines.
If these programs come with a list of requirements then the vendor
knows precisely what to implement in order to make such a port possible.
The choice of "standard" API is of course influenced by
the type of target machines one has in mind. Within the Unix world,
the increasing adoption of Open Standards, such as POSIX, means that
choosing a standard API which is implemented on a wide variety Unix
boxes is becoming easier. Similarly, choosing an API which will work
on most MSDOS machines should cause few problems. The difficulty is
that these are disjoint worlds; it is very difficult to find a standard
API which is implemented on both Unix and MSDOS machines. At present
not much can be done about this, it reflects the disjoint nature of
the computer market.
To develop a similar point : the drawback of choosing POSIX (for example)
as an API is that it restricts the range of possible target machines
to machines which implement POSIX. Other machines, for example, BSD
compliant machines, might offer the same functionality (albeit using
different methods), so they should be potential target machines, but
they have been excluded by the choice of API. One approach to the
problem is the "alternative API" approach. Both the POSIX
and the BSD variants are built into the program, but only one is selected
on any given target machine by means of conditional compilation. Under
our "equivalent functionality" definition of portability,
this is a program which is portable to both POSIX and BSD compliant
machines. But viewed in the light of the discussion above, if we regard
a program as a program-API pair, it could be regarded as two separate
programs combined on a single source code tree. A more interesting
approach would be to try to abstract out what exactly the functionality
which both POSIX and BSD offer is and use that as the API. Then instead
of two separate APIs we would have a single API with two broad classes
of implementations. The advantage of this latter approach becomes
clear if wished to port the program to a machine which implements
neither POSIX nor BSD, but provides the equivalent functionality in
a third way.
As a simple example, both POSIX and BSD provide very similar methods
for scanning the entries of a directory. The main difference is that
the POSIX version is defined in
As an exercise to the reader, how many of your programs use names
from the following restricted namespaces (all drawn from ANSI, all
applying to all namespaces)?
Currently TDF does not have a neat way of solving the
None of this is intended as criticism of the ANSI or POSIX standards.
It merely shows some of the problems that can arise from the insufficient
separation of code.
Part of the TenDRA Web.2.1. Portable Programs
2.1.1. Definitions and Preliminary Discussion
Let us firstly say what we mean by a portable program. A program is
portable to a number of machines if it can be compiled to give the
same functionality on all those machines. Note that this does not
mean that exactly the same source code is used on all the machines.
One could envisage a program written in, say, 68020 assembly code
for a certain machine which has been translated into 80386 assembly
code for some other machine to give a program with exactly equivalent
functionality. This would, under our definition, be a program which
is portable to these two machines. At the other end of the scale,
the C program:
#include <stdio.h>
int main ()
{
fputs ( "Hello world\n", stdout ) ;
return ( 0 ) ;
}
which prints the message, "Hello world", onto the standard
output stream, will be portable to a vast range of machines without
any need for rewriting. Most of the portable programs we shall be
considering fall closer to the latter end of the spectrum - they will
largely consist of target independent source with small sections of
target dependent source for those constructs for which target independent
expression is either impossible or of inadequate efficiency.2.1.2. Separation and Combination of Code
So why is the second example above more portable (in the sense of
more easily ported to a new machine) than the first? The first, obvious,
point to be made is that it is written in a high-level language, C,
rather than the low-level languages, 68020 and 80386 assembly codes,
used in the first example. By using a high-level language we have
abstracted out the details of the processor to be used and expressed
the program in an architecture neutral form. It is one of the jobs
of the compiler on the target machine to transform this high-level
representation into the appropriate machine dependent low-level representation.
fputs and stdout,
representing the procedure to output a string and the standard output
stream respectively, are left undefined. Instead the header stdio.h
is included on the understanding that it contains the specification
of these objects.
typedef struct {
int __cnt ;
unsigned char *__ptr ;
unsigned char *__base ;
short __flag ;
char __file ;
} FILE ;
extern FILE __iob [60] ;
#define stdout ( &__iob [1] )
extern int fputs ( const char *, FILE * ) ;
meaning that the type FILE is defined by the given structure,
__iob is an external array of 60 FILE's,
stdout is a pointer to the second element of this array,
and that fputs is an external procedure which takes a
const char * and a FILE * and returns an
int. On a different machine, the details may be different
(exactly what we can, or cannot, assume is the same on all target
machines is discussed below).FILE
and the value stdout (in terms of __iob),
but still leaves the precise definitions of __iob and
fputs still unresolved (although we do know their types).
The definitions of these values are not provided until the final phase
of the compilation - linking - where they are linked in from the precompiled
system libraries.stdio.h.
If we had also included the definitions of __iob and,
more particularly, fputs, things would have been even
worse - the procedure for outputting a string to the screen is likely
to be highly target dependent.stdio.h, been able
to effectively separate the target independent part of our program
(the main program) from the target dependent part (the details of
stdout and fputs). It is one of the jobs
of the compiler to recombine these parts to produce a complete program.2.1.3. Application Programming Interfaces
As we have seen, the separation of the target dependent sections of
a program into the system headers and system libraries greatly facilitates
the construction of portable programs. What has been done is to define
an interface between the main program and the existing operating system
on the target machine in abstract terms. The program should then be
portable to any machine which implements this interface correctly.stdio.h
are a type FILE representing a file, an object stdout
of type FILE * representing the standard output file,
and a procedure fputs with prototype:
int fputs ( const char *s, FILE *f ) ;
which prints the string s to the file f.
This is an example of an Application Programming Interface (API).
Note that it can be split into two aspects, the syntactic (what they
are) and the semantic (what they mean). On any machine which implements
this API our program is both syntactically correct and does what we
expect it to.stdio.h above we see
that this machine implements this API correctly syntactically, but
not necessarily semantically. One would have to read the documentation
provided on the system to be sure of the semantics.2.1.4. Compilation Phases
The general plan for how to write the extreme example of a portable
program, namely one which contains no target dependent code, is now
clear. It is shown in the compilation diagram in Fig. 1 which represents
the traditional compilation process. This diagram is divided into
four sections. The left half of the diagram represents the actual
program and the right half the associated API. The top half of the
diagram represents target independent material - things which only
need to be done once - and the bottom half target dependent material
- things which need to be done on every target machine.
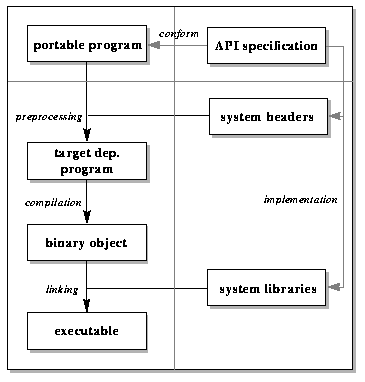
So, we write our target independent program (top left), conforming
to the target independent API specification (top right). All the compilation
actually takes place on the target machine. This machine must have
the API correctly implemented (bottom right). This implementation
will in general be in two parts - the system headers, providing type
definitions, macros, procedure prototypes and so on, and the system
libraries, providing the actual procedure definitions. Another way
of characterising this division is between syntax (the system headers)
and semantics (the system libraries).2.2. Portability Problems
We have set out a scheme whereby it should be possible to write portable
programs with a minimum of difficulties. So why, in reality, does
it cause so many problems? Recall that we are still primarily concerned
with programs which contain no target dependent code, although most
of the points raised apply by extension to all programs.2.2.1. Programming Problems
A first, obvious class of problems concern the program itself. It
is to be assumed that as many bugs as possible have been eliminated
by testing and debugging on at least one platform before a program
is considered as a candidate for being a portable program. But for
even the most self-contained program, working on one platform is no
guarantee of working on another. The program may use undefined behaviour
- using uninitialised values or dereferencing null pointers, for example
- or have built-in assumptions about the target machine - whether
it is big-endian or little-endian, or what the sizes of the basic
integer types are, for example. This latter point is going to become
increasingly important over the next couple of years as 64-bit architectures
begin to be introduced. How many existing programs implicitly assume
a 32-bit architecture?gcc)
or separate program checking tools such as lint, for
example, but this remains a very difficult area.2.2.2. Code Transformation Problems
We now move on from programming problems to compilation problems.
As we mentioned above, compilation may be regarded as a series of
phases of two types : combination and transformation. Transformation
of code - translating a program in one form into an equivalent program
in another form - may lead to a variety of problems. The code may
be transformed wrongly, so that the equivalence is broken (a compiler
bug), or in an unexpected manner (differing compiler interpretations),
or not at all, because it is not recognised as legitimate code (a
compiler limitation). The latter two problems are most likely when
the input is a high level language, with complex syntax and semantics.L suffix for long numeric literals
and not allowing members of enumeration types as array indexes are
among the problems drawn from my personal experience.gcc
has a single front end (C -> RTL) which may be combined with an
appropriate back end (RTL -> target) to form a suitable compiler
for a wide range of target machines. The existence of a single front
end virtually eliminates the problems of differing interpretation
of code and compiler quirks. It also reduces the exposure to bugs.
Instead of being exposed to the bugs in n separate compilers,
we are now only exposed to bugs in one half-compiler (the front end)
plus n half-compilers (the back ends) - a total of ( n +
1 ) / 2. (This calculation is not meant totally seriously, but
it is true in principle.) Front end bugs, when tracked down, also
only require a single workaround.2.2.3. Code Combination Problems
If code transformation problems may be regarded as a time consuming
irritation, involving the rewriting of sections of code or using a
different compiler, the second class of problems, those concerned
with the combination of code, are far more serious.
void index ( char * ) ;
which adds a string to this list in the appropriate position, using
strcmp from string.h to find it. This works
fine on most machines, but on some it gives the error:
Only 1 argument to macro 'index'
The reason for this is that the system version of string.h
contains the line:
#define index ( s, c ) strchr ( s, c )
But this is nothing to do with ANSI, this macro is defined for compatibility
with BSD._POSIX_SOURCE
are of some use, but are not always implemented and do not always
produce a complete separation; they are only provided for "standard"
APIs anyway). The problem above arose because there is no transitivity
rule of the form : if program P conforms to API A, and
API B extends A, then P conforms to B.
The only reason this is not true is these namespace problems.sys/stat.h contains the definition
of the structure struct stat, which includes several
members, amongst them:
time_t st_atime ;
representing the access time for the corresponding file. So the program:
#include <sys/types.h>
#include <sys/stat.h>
time_t st_atime ( struct stat *p )
{
return ( p->st_atime ) ;
}
should be perfectly valid - the procedure name st_atime
and the field selector st_atime occupy different namespaces
(see however the appendix on namespaces and APIs below). However at
least one popular operating system has the implementation:
struct stat {
....
union {
time_t st__sec ;
timestruc_t st__tim ;
} st_atim ;
....
} ;
#define st_atime st_atim.st__sec
This seems like a perfectly legitimate implementation. In the program
above the field selector st_atime is replaced by st_atim.st__sec
by the pre-processor, as intended, but unfortunately so is
the procedure name st_atime, leading to a syntax error.
#include <stdio.h>
int open ( char *nm )
{
int c, n = 0 ;
FILE *f = fopen ( nm, "r" ) ;
if ( f == NULL ) return ( -1 ) ;
while ( c = getc ( f ), c != EOF ) n++ ;
( void ) fclose ( f ) ;
return ( n ) ;
}
which opens the file nm, returning its size in bytes
if it exists and -1 otherwise. As a quick porting exercise, I compiled
it under six different operating systems. On three it worked correctly;
on one it returned -1 even when the file existed; and on two it crashed
with a segmentation error.fopen calls (either
directly or indirectly) the library routine open (which
is in POSIX, but not ANSI). The system linker, however, linked my
routine open instead of the system version, so the call
to fopen did not work correctly.2.2.4. API Problems
We have said that the API defines the interface between the program
and the standard library provided with the operating system on the
target machine. There are three main problems concerned with APIs.
The first, how to choose the API in the first place, is discussed
separately. Here we deal with the compilation aspects : how to check
that the program conforms to its API, and what to do about incorrect
API implementations on the target machine(s).2.2.4.1. API Checking
The problem of whether or not a program conforms to its API - not
using any objects from the operating system other than those specified
in the API, and not making any unwarranted assumptions about these
objects - is one which does not always receive sufficient attention,
mostly because the necessary checking tools do not exist (or at least
are not widely available). Compiling the program on a number of API
compliant machines merely checks the program against the system headers
for these machines. For a genuine portability check we need to check
against the abstract API description, thereby in effect checking against
all possible implementations.
#include <signal.h>
int sig = SIGKILL ;
will compile on most systems, despite the fact that SIGKILL
is not an ANSI signal, because SIGKILL is in POSIX, which
is also implemented in the system signal.h. Again, feature
test macros are of some use in trying to isolate the implementation
of a single API from the rest of the system headers. However they
are highly unlikely to detect the error in the following supposedly
POSIX compliant program which prints the entries of the directory
nm, together with their inode numbers:
#include <stdio.h>
#include <sys/types.h>
#include <dirent.h>
void listdir ( char *nm )
{
struct dirent *entry ;
DIR *dir = opendir ( nm ) ;
if ( dir == NULL ) return ;
while ( entry = readdir ( dir ), entry != NULL ) {
printf ( "%s : %d\n", entry->d_name, ( int ) entry->d_ino ) ;
}
( void ) closedir ( dir ) ;
return ;
}
This is not POSIX compliant because, whereas the d_name
field of struct dirent is in POSIX, the d_ino
field is not. It is however in XPG3, so it is likely to be in many
system implementations.
#include <stdio.h>
#include <stdlib.h>
div_t d = { 3, 4 } ;
int main ()
{
printf ( "%d,%d\n", d.quot, d.rem ) ;
return ( 0 ) ;
}
the ANSI standard specifies that the type div_t is a
structure containing two fields, quot and rem,
of type int, but it does not specify which order these
fields appear in, or indeed if there are other fields. Therefore the
initialisation of d is not portable. Again, the type
time_t is used to represent times in seconds since a
certain fixed date. On most systems this is implemented as long,
so it is tempting to use ( t & 1 ) to determine for
a time_t t whether this number of seconds
is odd or even. But ANSI actually says that time_t is
an arithmetic, not an integer, type, so it would be possible for it
to be implemented as double. But in this case (
t & 1 ) is not even type correct, so it is not a portable
way of finding out whether t is odd or even.2.2.4.2. API Implementation Errors
Undoubtedly the problem which causes the writer of portable programs
the greatest headache (and heartache) is that of incorrect API implementations.
However carefully you have chosen your API and checked that your program
conforms to it, you are still reliant on someone (usually the system
vendor) having implemented this API correctly on the target machine.
Machines which do not implement the API at all do not enter the equation
(they are not suitable target machines), what causes problems is incorrect
implementations. As the implementation may be divided into two parts
- system headers and system libraries - we shall similarly divide
our discussion. Inevitably the choice of examples is personal; anyone
who has ever attempted to port a program to a new machine is likely
to have their own favourite examples.2.2.4.3. System Header Problems
Some header problems are immediately apparent because they are syntactic
and cause the program to fail to compile. For example, values may
not be defined or be defined in the wrong place (not in the header
prescribed by the API).EXIT_SUCCESS
and EXIT_FAILURE are not always defined (ANSI specifies
that they should be in stdlib.h). It is tempting to change
exit (EXIT_FAILURE) to exit (1) because
"everyone knows" that EXIT_FAILURE is 1. But
this is to decrease the portability of the program because it ties
it to a particular class of implementations. A better workaround would
be:
#include <stdlib.h>
#ifndef EXIT_FAILURE
#define EXIT_FAILURE 1
#endif
which assumes that anyone choosing a non-standard value for EXIT_FAILURE
is more likely to put it in stdlib.h. Of course,
if one subsequently came across a machine on which not only is EXIT_FAILURE
not defined, but also the value it should have is not 1, then
it would be necessary to resort to #ifdef machine_name
statements. The same is true of all the API implementation problems
we shall be discussing : non-conformant machines require workarounds
involving conditional compilation. As more machines are considered,
so these conditional compilations multiply.SEEK_SET, SEEK_CUR and SEEK_END
should be defined in stdio.h, whereas POSIX specifies
that they should also be defined in unistd.h. It is not
uncommon to find machines on which they are defined in the latter
but not in the former. A possible workaround in this case would be:
#include <stdio.h>
#ifndef SEEK_SET
#include <unistd.h>
#endif
Of course, by including "unnecessary" headers like unistd.h
the risk of namespace clashes such as those discussed above
is increased.unistd.h declares functions
involving some of the types pid_t, uid_t
etc, defined in sys/types.h. Is it necessary to include
sys/types.h before including unistd.h, or
does unistd.h automatically include sys/types.h?
The approach of playing safe and including everything will normally
work, but this can lead to multiple inclusions of a header. This will
normally cause no problems because the system headers are protected
against multiple inclusions by means of macros, but it is not unknown
for certain headers to be left unprotected. Also not all header dependencies
are as clear cut as the one given, so that what headers need to be
included, and in what order, is in fact target dependent.
#define DBL_MAX 1.797693134862316E+308
in float.h on an IEEE-compliant machine is subtly wrong
- the given value does not fit into a double - the correct
value is:
#define DBL_MAX 1.7976931348623157E+308
Again, the type definition:
typedef int size_t ; /* ??? */
(sic) is not compliant with ANSI, which says that size_t
is an unsigned integer type. (I'm not sure if this is better or worse
than another system which defines ptrdiff_t to be unsigned
int when it is meant to be signed. This would mean that the
difference between any two pointers is always positive.) These particular
examples are irritating because it would have cost nothing to get
things right, correcting the value of DBL_MAX and changing
the definition of size_t to unsigned int.
These corrections are so minor that the modified system headers would
still be a valid interface for the existing system libraries (we shall
have more to say about this later). However it is not possible to
change the system headers, so it is necessary to build workarounds
into the program. Whereas in the first case it is possible to devise
such a workaround:
#include <float.h>
#ifdef machine_name
#undef DBL_MAX
#define DBL_MAX 1.7976931348623157E+308
#endif
for example, in the second, because size_t is defined
by a typedef it is virtually impossible to correct in
a simple fashion. Thus any program which relies on the fact that size_t
is unsigned will require considerable rewriting before it
can be ported to this machine.2.2.4.4. System Library Problems
The system header problems just discussed are primarily syntactic
problems. By contrast, system library problems are primarily semantic
- the provided library routines do not behave in the way specified
by the API. This makes them harder to detect. For example, consider
the routine:
void *realloc ( void *p, size_t s ) ;
which reallocates the block of memory p to have size
s bytes, returning the new block of memory. The ANSI
standard says that if p is the null pointer, then the
effect of realloc ( p, s ) is the same as malloc
( s ), that is, to allocate a new block of memory of size s.
This behaviour is exploited in the following program, in which the
routine add_char adds a character to the expanding array,
buffer:
#include <stdio.h>
#include <stdlib.h>
char *buffer = NULL ;
int buff_sz = 0, buff_posn = 0 ;
void add_char ( char c )
{
if ( buff_posn >= buff_sz ) {
buff_sz += 100 ;
buffer = ( char * ) realloc ( ( void * ) buffer, buff_sz * sizeof ( char ) ) ;
if ( buffer == NULL ) {
fprintf ( stderr, "Memory allocation error\n" ) ;
exit ( EXIT_FAILURE ) ;
}
}
buffer [ buff_posn++ ] = c ;
return ;
}
On the first call of add_char, buffer is
set to a real block of memory (as opposed to NULL) by
a call of the form realloc ( NULL, s ). This is extremely
convenient and efficient - if it was not for this behaviour we would
have to have an explicit initialisation of buffer, either
as a special case in add_char or in a separate initialisation
routine.realloc ( NULL,
s ) having been implemented precisely as described in the ANSI
standard. The first indication that this is not so on a particular
target machine might be when the program is compiled and run on that
machine for the first time and does not perform as expected. To track
the problem down will demand time debugging the program.realloc
a number of possible workarounds are possible. Perhaps the most interesting
is to replace the inclusion of stdlib.h by the following:
#include <stdlib.h>
#ifdef machine_name
#define realloc ( p, s )\
( ( p ) ? ( realloc ) ( p, s ) : malloc ( s ) )
#endif
where realloc ( p, s ) is redefined as a macro which
is the result of the procedure realloc if p
is not null, and malloc ( s ) otherwise. (In fact this
macro will not always have the desired effect, although it does in
this case. Why (exercise)?)2.3. APIs and Portability
We now return to our discussion of the general issues involved in
portability to more closely examine the role of the API.,
but if we wish the API to fully describe the interface between the
program and the target machine, we must also say that whether or not
the macro mips is defined is part of the API. Like the
rest of the API, this has a semantic aspect as well as a syntactic
- in this case that mips is only defined on mips machines.
Where it differs is in its implementation. Whereas the main part of
the API is implemented in the system headers and the system libraries,
the implementation of either defining, or not defining, mips
ultimately rests with the person performing the compilation. (In this
particular example, the macro mips is normally built
into the compiler on mips machines, but this is only a convention.)unsigned int contains
32 bits:
#include <stdio.h>
#include "config.h"
#ifndef SLOW_SHIFT
#define MSB ( a ) ( ( unsigned char ) ( a >> 24 ) )
#else
#ifdef BIG_ENDIAN
#define MSB ( a ) *( ( unsigned char * ) &( a ) )
#else
#define MSB ( a ) *( ( unsigned char * ) &( a ) + 3 )
#endif
#endif
unsigned int x = 100000000 ;
int main ()
{
printf ( "%u\n", MSB ( x ) ) ;
return ( 0 ) ;
}
The intention is to print the most significant byte of x.
Three alternative definitions of the macro MSB used to
extract this value are provided. The first, if SLOW_SHIFT
is not defined, is simply to shift the value right by 24 bits. This
will work on all 32-bit machines, but may be inefficient (depending
on the nature of the machine's shift instruction). So two alternatives
are provided. An unsigned int is assumed to consist of
four unsigned char's. On a big-endian machine, the most
significant byte is the first of these unsigned char's;
on a little-endian machine it is the fourth. The second definition
of MSB is intended to reflect the former case, and the
third the latter.MSB provided by the programmer. This
is done by either defining, or not defining, the macros SLOW_SHIFT
and BIG_ENDIAN. This could be done as command line options,
but we have chosen to reflect another commonly used device, the configuration
file. For each target machine, the programmer provides a version of
the file config.h which defines the appropriate combination
of the macros SLOW_SHIFT and BIG_ENDIAN.
The person performing the compilation simply chooses the appropriate
config.h for the target machine.MSB, but it could also be argued that it is the macros
SLOW_SHIFT and BIG_ENDIAN. The former more
accurately describes the target dependent code, but is only implemented
indirectly, via the latter.2.3.2. Making APIs Explicit
As we have said, every program has an API even if it is implicit rather
than explicit. Every system header included, every type or value used
from it, and every library routine used, adds to the system-defined
component of the API, and every conditional compilation adds to the
user-defined component. What making the API explicit does is to encapsulate
the set of requirements that the program has of the target machine
(including requirements like, I need to know whether or not the target
machine is big-endian, as well as, I need fputs to be
implemented as in the ANSI standard). By making these requirements
explicit it is made absolutely clear what is needed on a target machine
if a program is to be ported to it. If the requirements are not explicit
this can only be found by trial and error. This is what we meant earlier
by saying that a program without an explicit API is only portable
by accident.2.3.3. Choosing an API
So how does one go about choosing an API? In a sense the user-defined
component is easier to specify than the system-defined component because
it is less tied to particular implementation models. What is required
is to abstract out what exactly needs to be done in a target dependent
manner and to decide how best to separate it out. The most difficult
problem is how to make the implementation of this API as simple as
possible for the person performing the compilation, if necessary providing
a number of alternative implementations to choose between and a simple
method of making this choice (for example, the config.h
file above). With the system-defined component the question is more
likely to be, how do the various target machines I have in mind implement
what I want to do? The abstraction of this is usually to choose a
standard and widely implemented API, such as POSIX, which provides
all the necessary functionality.dirent.h and uses a structure
called struct dirent, whereas the BSD version is defined
in sys/dir.h and calls the corresponding structure struct
direct. The actual routines for manipulating directories are
the same in both cases. So the only abstraction required to unify
these two APIs is to introduce an abstract type, dir_entry
say, which can be defined by:
typedef struct dirent dir_entry ;
on POSIX machines, and:
typedef struct direct dir_entry ;
on BSD machines. Note how this portion of the API crosses the system-user
boundary. The object dir_entry is defined in terms of
the objects in the system headers, but the precise definition depends
on a user-defined value (whether the target machine implements POSIX
or BSD).
is[a-z][0-9a-z_A-Z]+ (ctype.h)
to[a-z][0-9a-z_A-Z]+ (ctype.h)
str[a-z][0-9a-z_A-Z]+ (stdlib.h)
With the TDF approach of describing APIs in abstract terms using the
#pragma token syntax most of these namespace restrictions
are seen to be superfluous. When a target independent header is included
precisely the objects defined in that header in that version of the
API appear in the namespace. There are no worries about what else
might happen to be in the header, because there is nothing else. Also
implementation details are separated off to the TDF library building,
so possible namespace pollution through particular implementations
does not arise.va_list
problem. The present target independent headers use a similar workaround
to that described above (exploiting a reserved namespace). (See the
footnote in section 3.4.1.1.)
Crown
Copyright © 1998.